Quasi-experiments: 인과 관계를 추정하는 방법
A/B 테스트를 적용하기 어려울 때는 어떻게 할까?
A/B 테스트를 적용하기 어려울 때, 이벤트 효과 추정하기와, Beyond A/B Testing: Primer on Causal Inference (Towards data science) 를 참고했다.
한국어로 잘 설명된 레퍼런스는 Causal inference cheat sheet for data scientists 번역본을 추천한다.
Experiments: A/B test (w/ 좋은 실험 설계)

상관관계를 인과관계로 검증하기 위한 방법 중 하나로, 매스프레소도 현재 주요하게 사용하는 방법이다.
좋은 실험 설계를 바탕으로 A/B test를 진행할 때, 이벤트로 인한 효과를 가장 정확하게 측정할 수 있다.
하지만 A/B test를 진행할 수 없는 상황이 존재한다.
[1] Spilover Effect : 실험군에 적용한 결과가 대조군에 영향을 미칠 때
- A는 실험군, B는 대조군, 둘은 SNS 상에서 친구
- A의 피드에 실험이 적용되어 어떤 상품이 노출되었고, A가 그걸 보고 구매했다
- B는 대조군이었는데 SNS 친구인 A가 클릭한 상품이 피드에 노출되어 구매했다
- 실험군의 행동이 대조군에게까지 영향을 미치는 구조(피드로 연결)이기 때문에 명확한 인과관계를 파악하기 어려워진다.
[2] 비용 등 현실적인 문제
[3] 윤리적 문제
- 페이스북의 감정 조작 실험
- 페이스북 사용자에게 특정 감정과 관련된 게시물(긍정, 부정)들이 노출되는 것이 실제 사용자의 감정에 어떤 영향을 미치는지 실험 진행
- 미국 국립 과학원 회보(PNAS)의 대규모 감정 전염 실험에 페이스북이 협조함.
Quasi-experiments : A/B test를 할 수 없을 때 대안들
Quasi-experiments 는 준 실험 또는 유사 실험이라고 부른다. 자세한 개념은 아래와 같다.
RCT(Randomized Controlled Trials, 무작위 배치) 와 같이 통제 원칙(대조군을 두어 여러 외생 변수를 조절)을 지키지는 않았으나, 유사하게 조작(특정 조치를 받은 그룹, 그렇지 않은 그룹)을 설정할 수 있는 실험

1. Difference in Differences (DID, 이중차분법)
Econometrics and Quantitative research에서 사용되어온 통계학 방법이며, Controlled before-and-after 이라고도 불렸다.
정책시행의 전후를 비교하여 그 효과를 분석하는 기본적인 모형으로 가장 흔히 사용한다.
DID is a useful technique to use when randomization on the individual level(RCT) is not possible. (passage of law, enactment of policy, or large-scale program implementation)
대신 사용할 때에 다양한 가정이 필요하다.
DID assumptions
- OLS assumptions: 최소 자승 회귀에서 적용되는 클래식한 가정들이 전부 적용된다고 함. All the assumptions of the OLS model apply equally to DID.
- Parallel trend assumption: Treatment and control groups have Parallel Trends in outcome. In absence of treatment, the unobserved differences between treatment and control groups are the same overtime.
- Stable composition of groups: 실험군, 대조군 그룹의 구성이 시간이 지나도 stable할 것. The composition of intervention and comparison groups is stable for repeated cross-sectional design.
- No spillover effects: 위에서 얘기한, 실험군에 가한 조치가 대조군에 영향이 엎질러지지 않아야 함.
예시를 2가지 들어보자.
예시 1. 이벤트 영향이 없던 시즌을 대조군으로 사용
측정 컴포넌트:
- 이벤트가 있었던 시즌의 이벤트 기간 전/후 차이
- 이벤트가 없었던 시즌의 이벤트 기간 전/후 차이
Parallel trend assumption:
- 이벤트가 있었던 시즌, 없었던 시즌의 Outcome(y) 추이가 기본적으로 유사하다.
예시 2. 정책 변경이 없는 다른 국가를 대조군으로 사용

측정 컴포넌트:
- 정책 변경이 있었던 국가의 정책 변경 연도 전/후 차이
- 정책 변경이 없었던 국가의 정책 변경 연도 전/후 차이
Parallel trend assumption:
- 이벤트가 있었던 국가(Basque), 없었던 국가(Catulana)의 GDP per capita (y) 추이가 기본적으로 유사하다.
BEST PRACTICES of DID
DID를 논리적으로 결함이 없도록 사용하는 방식에 대해 간략히 기술한 내용이다.
- Be sure outcome trend did not influence allocation of the treatment/intervention- Acquire more data points before and after to test parallel trend assumption- Use linear probability model to help with interpretability- Be sure to examine composition of population in treatment/intervention and control groups before and after intervention- Use robust standard errors to account for autocorrelation between pre/post in same individual- Perform sub-analysis to see if intervention had similar/different effect on components of the outcome
2. Synthetic Control Method (SCM)
Inferring the effect of an event using CausalImpact by Kay Brodersen 세션을 참고했다. (Google)
핵심 문제: 2015년 1월 국가 A에서 보도 자료를 발표했다. 이 보도 자료 발표의 효과는 얼마인가?

문제를 하나씩 풀어나가보자.
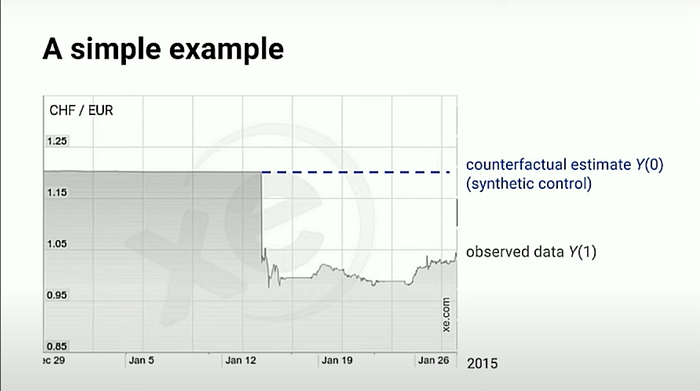
- Causal Inference 관점에서 생각해보자. 만약 보도 자료 발표의 개입이 없었다면 → 파란 라인 Y(0)이 정상적인 값이었을 것이다. 이 값은 실제로 존재하지 않기 때문에 counterfactual estimate 라고 칭한다.
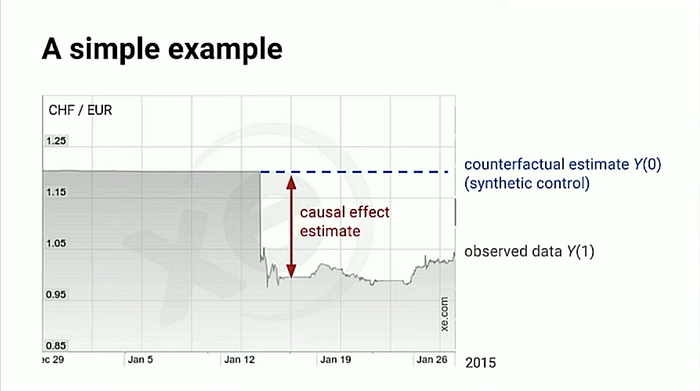
- 예측하여 가상의 control group을 생성했으니, observed data인 treatment group과의 차이가 곧 우리가 원하는 causal effect estimate (추정 효과)가 된다.
- Synthetic Control은, 보도 자료 발표의 개입이 없었을 경우의 → counterfactual estimate Y(0)을 예측하고 실제로는 존재하지 않는 control group인 것 처럼 활용하는 것이 핵심이다.
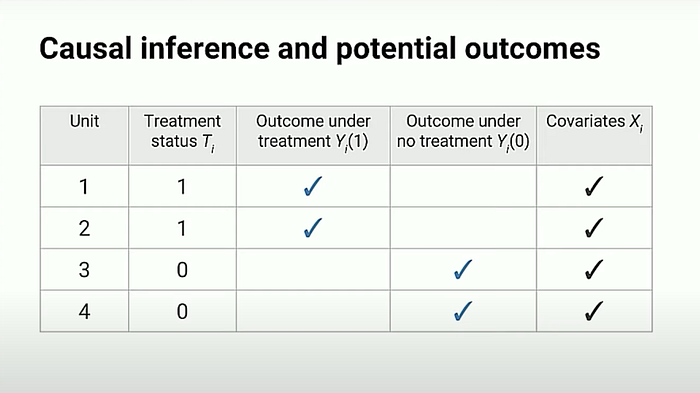
- Unit은 데이터에 따라 다른데, 의료 실험의 경우 피실험자 개인 1명이 하나의 Unit이 되고, 웹 트래픽 실험의 경우 cookie 또는 user_id가 된다.
- 이 경우 T-TEST, ANOVA 를 사용할 수 있고, 이 두 방법론으로 측정하는 효과는 observed outcome in treatment group, control group 을 비교하는 것에서 나온다.
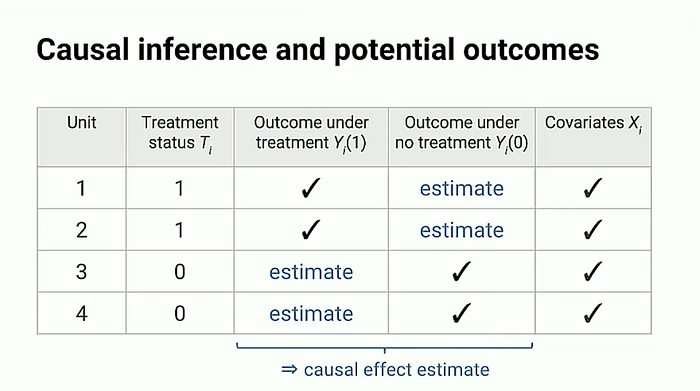
- Covariates Xi 는 Treatment에는 영향을 받지 않는 공변량 변수들을 의미한다.
- Treatment 이전, 이후 데이터와 공변량과의 조합을 통해 비어있는 값들(counter factual estimates)을 예측한다.
- T-TEST, ANOVA보다 더 융통성 있고 통계적으로 타당성이 높은 방식으로 인과 효과를 추정할 수 있다.
- SCM은 분석하고자 하는 단위(unit)의 비교 대상으로서 단일 개체(a single unit)보다는 개체들의 조합(a combination of units)이 보다 적합할 수 있다는 수리적인 개념에서 출발했다.

- 하지만 현실 데이터는 이렇다. 여러 제약들로 인해서 대조군이 없고 실험군 조차 수가 적다.

- Estimation을 반복하면 여러 iteration마다 Yi(1) — Yi(0) 의 causal effect estimate 가 나오고, 그 causal effect estimate가 모여 우측의 분포를 그릴 것이다.
- 여기서 베이지안 방법론이 사용된다. p(causal effect estimate | Y, X, T ) 사후 추론 값에 대한 신뢰 구간(빈도주의 통계학에서는 Confidence Interval, 베이지안 통계학에서는 Credible Interval) 을 만들어서 근거로 제공한다.
- 베이지안 관점의 신뢰 구간 추정에 대해서는 레퍼런스 를 참고!
그러면 synthetic control은 어느 상황에서 사용하나?
- the social events take place at the aggregated level, e.g. county, state, province.
- only one treated case and a few control cases.
- Due to these two traits, the SCM is the to-go method when it comes to large-scale program evaluation (e.g., California’s Tobacco Control Program, Evaluating Place-Based Crime Interventions)
3. Causal Impact (Google)
위 Synthetic Control Method 설명 (Google 발표 슬라이드) 에서 이어진다. 이론은 towards data science reference 을 참고했다.

X1, X2는 other time series which are related to our outcome of interest를 의미한다.
X1, X2의 조건
- should not be affected by the treatment
- should be predictive of our outcome Y (correlated)
- 예시로, 해당 산업의 웹 검색 트래픽, 경쟁사 제품의 웹 검색 트래픽, 주가, 날씨 등이 될 수 있다.
이 X1, X2 를 찾는 것이 가장 중요하다. (발표자는 진입하지 않은 시장에서의 정보, 주가, 노동 시장, 날씨, 구글 트렌드 of 산업, 프러덕트 를 추천했다.)
절차
[1] pre-period에서 model selection 하여 X1, X2를 통해 Y를 예측하도록 학습한다. (모델은 Statistical model, ML, DL 무엇이든지) 여기서 causal impact 패키지는 bayesian structured time series model을 사용한다.
[2] 예측: [1] 에서 train한 모델을 post-period에서 적용하여 예측한다.
Causal Impact 소개
다양한 준 실험 연구 방법이 있지만, 위 글에 의하면 Google의 Causal Impact 패키지가 아주 강력하고 융통성이 있어 대부분의 준 실험 연구 상황 방법들을 커버한다고 한다. 특히 Causal Impact 패키지는 광고 퍼포먼스 측정과 프라이싱(가격) 실험에서 유용하다.
Causal Impact — SCM(Synthetic Control Method)과 공통점
- Control group의 데이터를 활용해 treatment group의 counter-factual 데이터를 가상으로 생성해, 만일 treatment가 일어나지 않았다면 데이터의 트렌드가 어떠했을 지 예측한다. (그 반대 방향도)
Causal Impact — SCM과의 차이점
- SCM: 이벤트 이전의 데이터로 이벤트 이후로 예측한다.
pre-treatment variables - Causal Impact: 이벤트 전후 전체 기간의 데이터를 바탕으로 학습하여 이벤트 기간에 이벤트가 없었을 경우를 시뮬레이션한다.
pre and post-treatment time series of predictor variables
Causal Impact 로직
- 이벤트와 정책 변경과 같은 개입(intervention)이 있는 시계열 관측치 데이터 Y를 준비한다.
- 연관된 다른 변수들도 준비한다. (발표자는 진입하지 않은 시장에서의 정보, 주가, 노동 시장, 날씨, 구글 트렌드 of 산업, 프러덕트 를 추천함)
- 여러 변수를 동시에 사전 요인으로 사용해, 이 요인들이 실제로 얼마나 Y에 영향을 끼치는지, 변수들은 서로 어떻게 영향을 미치는지 파악하고, 그 기반으로 전체 트렌드인 Y가 어떻게 변화할지를 예측한다.
주요 가정
- Y에서 일어나는 변화는 Synthetic control 값을 예측할 때 들어가는 변수들에 영향을 주지 않는다.
- Y와 변수의 관계는 개입(intervention)이 없었다면 계속되었을 것이다.
제안하는 데이터의 조건 (Rule of thumb)
- 이벤트 이후 기간이 1 ~ 3주 정도의 길이일 때 가장 이상적이다.
- 이벤트 이전 기간이 이벤트 이후 기간의 3–4배 가까이 길어야 좋다.
- 주요한 구조적인 변화가 전체 기간 통틀어서 없을 것.
- “Garbage in, garbage out” 을 강조한다. Causal Impact 모델이 예측한 효과가 더 타당성을 가질 수 있도록 튜닝하는 과정은 대부분 counterfactual 데이터를 예측하는 변수를 찾고 검증하는 과정이다. 이 변수 는 주로 사람의 판단으로 구성되는데, 2. Ladder of Causality 에서 이야기했듯이 변수와 예측치의 인과 관계를 고민해본 후 변수를 추가해주는 것이 중요하다.
레퍼런스로 삼고 시작하기 좋은 Example
- 구글에서 제공하는 introductory ipython notebook
4. 그 외: Interrupted time-series, Regression discontinuity design
5. 마무리로 라이브러리 추천 ️
참고한 글은 Tools and libraries for causality 이고, 리서치 해본 바 현재는 3개 정도가 메인이다.
Causal Impact (Google’s, 2015)
- https://github.com/dafiti/causalimpact — Connect to preview
- 세션 유튜브: https://www.youtube.com/watch?v=GTgZfCltMm8&list=LL&index=3&ab_channel=BigThingsConference
- 한국어 글: https://cojette.github.io/timeseries/
DoWhy documentation (Microsoft’s, 2018)
Causal ML documentation (Uber’s, 2020)

